L'optimisation des requêtes avec EXPLAIN
La performance des requêtes peut être affectée par un grand nombre d'éléments. Certains peuvent être contrôlés par l'utilisateur, d'autres sont fondamentaux au concept sous-jacent du système.
PostgreSQL réalise un plan de requête pour chaque requête qu'il reçoit. Choisir le bon plan correspondant à la structure de la requête et aux propriétés des données est absolument critique pour de bonnes performances, donc le système inclut un planificateur complexe qui tente de choisir les bons plans.
Optimiser les requêtes peut-être un art difficile, mais il est bon de connaître les rudiments.
Vous pouvez utiliser la commande EXPLAIN pour voir quel plan de requête le planificateur crée pour une requête particulière.
On pourra également lire le chapitre sur l'utilisation des index.
Le cours de Stéphane CROZAT constitue également une bonne introduction non orienté sur la géomatique.
Exemple d'optimisation avec création d'index
Sous PgAdmin, exécuter l'ordre SQL suivant sur la table FR_communes du schéma travail de la base stageXX :
select * from travail."FR_communes" where "Code_Commune" = '023' and "Statut" = 'Commune simple' and "Nom_Région" = 'AQUITAINE'
noter le temps qui apparaît en bas à droite ou dans l'onglet 'messages' :

En fait si on re-execute plusieurs fois la requête on s’aperçoit d'une assez grande dispersion des résultats, mais l'ordre de grandeur reste le même.
Dans notre cas le temps d'exécution moyen est d'environ 140 ms.
Lançer maintenant la requête avec l'option EXPLAIN :

vous devez voir apparaître dans l'onglet 'EXPLAIN'

En positionnant le curseur sur l'icône des explications détaillées apparaissent :
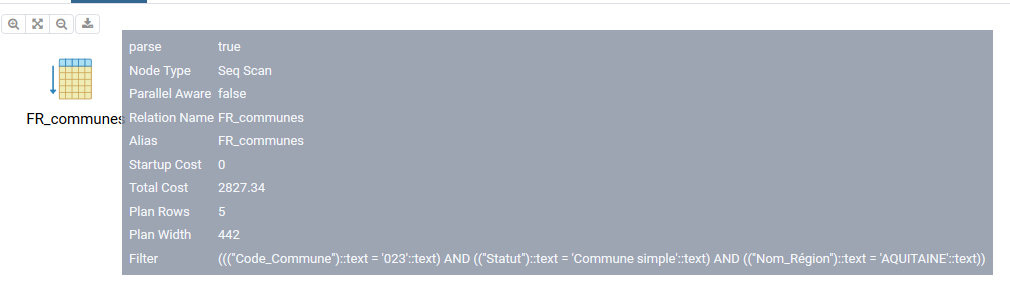
Seq scan : indique que le moteur SQLde PostgreSQL execute un balayage séquentiel sur la table FR_communes
startup cost : est le coût estimé de lancement
Total cost : est le coût estimé du scan (les coûts sont estimés en unité arbitraire)
Plan rows : indique que 5 lignes sont retournées
Plan width : longueur estimée en octets
EXPLAIN fourni des données estimées.
On peut exécuter EXPLAIN ANALYZE qui lui va exécuter la requête et fournir les coûts mesurés 

Ajoutons maintenant un index (de type btree) sur le champs"Statut"

puis, réexécuter la requête SQL
Normalement vous devez constater un temps d’exécution plus court (le cas échéant exécuter plusieurs fois la requête pour avoir un temps moyen).
Relancer le EXPLAIN

Le moteur de PostgreSQL commence par balayer la table d'index sur le statut pour un coût de 4.94, puis balaye uniquement les enregistrements de la table FR_communes correspondant à la condition sur statut pour un coût de 299.15 (coût total) - 4.94 (coût du balayage de la table d'index).
Le coût total est de 299.15 et donc très inférieur au coût sans l'index.
Il se peut cependant que le planificateur n'utilise pas ce nouvel index dans votre cas particulier.
en effet les index ne sont pas systématiquement utilisés. Voir la documentation PostgreSQL.
Ajouter maintenant un index supplémentaire sur le champ "Code_Commune" et un autre sur le champ "Nom_Région"
relancer la requête et le EXPLAIN :

Si on survole l'icône finale à droite, on constate que le coût global est maintenant de 82.21
Le planificateur a choisi une stratégie :
balayage de l'index sur le champ Nom_Région en 57.66
balayage de l'index id_commune en 4.93
ET (Bitmap And) entre les deux résultats ci-dessus en 0
balayage des lignes de la table FR_Communes correspondantes en ajoutant le filtre sur le Statut en (82.21- 62.84) = 19.77
Pour un total de 82.21.
Le planificateur aurait pu choisir une autre stratégie en inversant le rôle d'un ou de deux des index. Il base sa stratégie sur les données statistiques qu'il maintient sur les tables.
Une commande VACCUM ANALYZE que l'on peut lancer sur la base stageXX à partir du menu Outils -> Maintenance
permet de remettre à jour les statistiques sur les tables.
Tentons maintenant une autre stratégie d'optimisation en utilisant plutôt un index composite.
Supprimer les index créés sur la table (clic droit sur l'index -> supprimer)
créer un index qui porte sur les champs statut et Nom_Région et Code_commune :

Relancer l'analyse sur la requête :

La stratégie est maintenant de balayer l'index composite, puis de rechercher les enregistrements correspondant dans la table FR_communes pour un coût total de 18.13
A comparer avec les résultats précédents.
Bien entendu il ne faut pas abuser de la création des index (occupation disque et ralentissement des requêtes en modifications), mais les utiliser a bon escient après avoir diagnostiqué les requêtes coûteuses les plus fréquentes.
Complément :
EXPLAIN fourni des temps estimés, EXPLAIN ANALYZE fourni les temps observés (exécute la requête), ce qui est beaucoup plus précis mais coûteux en temps.
Il est également possible d'avoir plus de détails avec EXPLAIN ANALYZE VERBOSE
ou directement en SQL :
explain analyze verbose select * from travail."FR_communes" where "Code_Commune" = '023' and "Statut" = 'Commune simple' and "Nom_Région" = 'AQUITAINE'
qui renvoi :
"Index Scan using id_composite on travail."FR_communes" (cost=0.41..18.13 rows=5 width=442) (actual time=0.024..0.032 rows=5 loops=1)"
" Output: id, geom, "Code_Commune", "INSEE_Commune", "Nom_Commune", "Statut", "Population", "Superficie", "Altitude_Moyenne", "Code_Canton", "Code_dpt_arr_can", "Code_Arrondissement", "Code_dpt_arr", "Code_Département", "Nom_Département", "Code_Région", "Nom_Région""
" Index Cond: ((("FR_communes"."Statut")::text = 'Commune simple'::text) AND (("FR_communes"."Nom_Région")::text = 'AQUITAINE'::text) AND (("FR_communes"."Code_Commune")::text = '023'::text))"
"Planning time: 0.104 ms"
"Execution time: 0.056 ms"
Complément :
PostgreSQL permet de mettre dans le fichier de log, les requêtes ayant plus pris plus d'un certain temps. Cette option se configure via l'entrée log_min_duration_statement du fichier de configuration PostgreSQL.
A noter également un site qui permet de mettre en exergue les parties les plus coûteuses d'un plan d'analyse.
On trouvera également des explications très détaillées sur ce site avec par exemple la description des opérations des plans d'analyse.
Complément : Indexation des géométries dans des requêtes complexes.
Si on utilise des sous-requêtes qui calculent des géométries (st_intersection, st_buffer,...) pour ensuite les croiser avec des grosses tables (ex : département entier), il faut savoir que les géométries calculées ne sont pas indexées. Une solution d'optimisation peut alors être de créer une table résultat temporaire qui pourra être elle, être indexée :
CREATE TEMP TABLE Matable AS... , puis CREATE INDEX monIndex ON MaTable USING GIST (the_geom),
au lieu de WITH Matable AS (SELECT...) qui ne permet pas de réaliser la phase d'indexation.
Exemple :
Si on créé un index sur « Matable »
---creation d'un index sur la géométrie de "matable"
CREATE INDEX matable_the_geom_idx ON matable USING gist (the_geom);
Puis qu'on utilise, par exemple, un syntaxe CTE :
WITH tampons AS (SELECT st_buffer(the_geom) as geom from ma_table)
SELECT * from tampons where ST_area(geom) <100 ;
L'index n'est pas mobilisé puisque le WHERE n'utilise pas la géométrie indexée the_geom, mais la géométrie calculée geom=st_buffer(the_geom)
Il pourrait donc être opportun de créer une table temporaire « tampons »
plutôt que d'utiliser le WITH.