Présentation
Interface générale
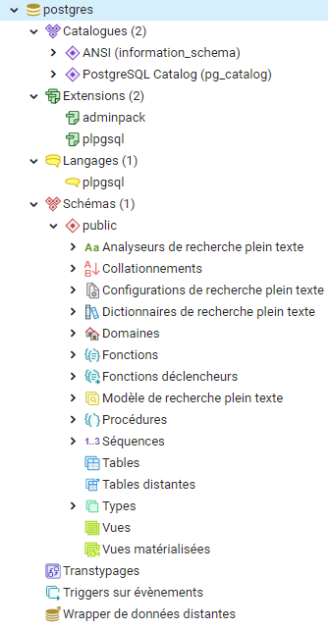
L'interface de pgAdmin se découpe en 4 zones distinctes :
en haut : les menus et les raccourcis,
à gauche : le navigateur d'objets qui est l'arborescence du serveur de bases de données (bases, tables, schémas, vues...),
au centre : les propriétés associées à l'objet sélectionné à gauche,
à droite : le panneau SQL qui contient la définition SQL de l'objet sélectionné.

Lors de la connexion au serveur existant, trois groupes d'éléments sont disponibles dans le navigateur d'objets (partie de gauche) :
les bases de données existantes : la base « postgres » installée est la base de référence, qu'il ne faut jamais modifier ; elle sert de modèle pour la création de toutes les autres bases de données.
les tablespaces : l'espace de stockage des tables et index. Il indique le répertoire d'écriture des fichiers. Cette partie est gérée par l'administrateur de la base de donnée.
les rôles : les rôles, sont les droits alloués aux différents utilisateurs du serveur de bases de données. Les rôles de connexions correspondent aux différents utilisateurs, et les rôles groupe, aux groupes d'utilisateurs. Cette partie est également gérée par l'administrateur de la base de donnée. Par défaut, un seul rôle de connexion, celui de l'utilisateur « postgres » , a tous les droits. Il existe des groupes de connexions, notés "pg_..." utilisés pour la maintenance du serveur.
Note : généralement, sur un serveur en production, l'utilisateur postgres est désactivé à la connexion, pour éviter les problèmes de sécurité. Il est préférable de créer un autre super-administrateur.
La base de données PostgreSQL
La base de données « postgres » est le modèle de création de toutes les autres bases de données. Cela doit être indiqué lors de toute création de nouvelle base de donnée, dans les définitions de la base de données.
Chaque base de données créée sera alors une copie de la base « postgres » et héritera de ses caractéristiques :
les extensions (extensions) : fonctionnalités supplémentaires ajoutées à PostgreSQL. Nous en observerons une particulièrement : PostGIS.
l'extension adminpack offre des outils d'administration ; on retrouve cette extension dans la base par défaut « postgres » .
l'extension plpgsql sera intégrée automatiquement lors d'une création de base de données sur le modèle le la base par défaut. Elle permet d'écrire dans le langage PL / pgSQL, utile dans la création de fonctions.
les schémas (schemas) : dans l'arborescence de la base de données, ce sont les sous-ensembles qui contiendront les données (tables, vues, séquences...). Ce sont les éléments principaux qui seront abordés dans cette formation.
Les éléments suivants ne seront pas abordés dans la formation :
les catalogues (catalogs) : correspondent aux catalogues de métadonnées sur les schémas et les tables. On y trouve aussi toutes les fonctions de base disponibles dans PostgreSQL.
les triggers sur événements (events triggers) : actions qui se déclenchent automatiquement sur la base de données lorsque d'autres événements ciblés se déclenchent.
les transcryptages (casts) : permet de convertir une valeur d'un type de données dans un autre type de données.
les wrapper de données distances (foreign data wrapper) : adaptateur pour associer des données PostgreSQL à des données stockées sur une autre source de données.
Le schéma
Le schéma par défaut dans la base de données est le schéma « public ». Ce sous élément de la base de données contient les tables (en considérant l'information géographique, les tables sont l'équivalent des couches vecteurs et rasters).
Les schémas sont alors comparables à des dossiers où sont stockées les couches de données.
Les schémas sont composés de plusieurs éléments qui les caractérisent. Tous les éléments suivant sont paramétrables pour le schéma auquel ils appartiennent et lui-seul :

collationnements : contrôler les ordres de tris
domaines : contraintes spécifiques sur un type de données
FTS (configurations, dictionnaires, analyseurs, modèles) : paramètres de recherches plein texte
fonctions : fonctions/procédures supplémentaires aux fonctions de bases spécifiques au schéma. Exemple : on y trouvera ultérieurement les fonctions d'analyse spatiale
fonctions déclencheurs (trigger) : fonctions qui se déclencheront automatiquement lors d'une action sur une table
procédures : procédures sur les données. Permet, par exemple, de renvoyer des éléments spécifiques d'une table.
séquences : suites de nombres propres applicables à des champs. Exemple : auto-incrémentation
tables : tables de données
tables distantes : tables de données issues de sources de données étrangères
types : créer des types de données personnalisés
vues : vues sur les tables. Ce sont des requêtes sur une ou plusieurs tables. Les vues se mettent à jour lors de modifications des tables sur lesquelles elles sont basées.
vues matérialisées : vues sur les tables. Les vues matérialisées NE se mettent PAS à jour lors de modifications des tables sur lesquelles elles sont basées : idéal pour des vues à ne mettre à jour que rarement, puisque les temps de calculs n'existent plus contrairement aux vues simples.
Bilan
Un serveur de bases de données, peut contenir plusieurs bases de données. Ces dernières sont cloisonnées entre elles :
les données peuvent se transférer d'une base de données à une autre, mais cela reste une action complexe à la charge de administrateur (les données d'un serveur à l'autre ne communiquent pas),
la gestion des utilisateurs se réalise à l'intérieur d'une même bases de données.
Une base de données peut contenir plusieurs schémas :
ils permettent une meilleure gestion des utilisateurs de la base de données,
ils n'empêchent pas le transfert ou l'appel de données (tables) d'un schéma à l'autre,
ils ne peuvent pas être imbriqués (ils sont tous au même niveau).
Un schéma peut contenir plusieurs tables. Les tables peuvent êtres liées entre elles ou indépendantes les unes des autres.
La base de données PostGIS
La base de données PostGIS est une base de données PostgreSQL classique, comme la base par défaut « postgres » , à laquelle on a ajouté l'extension PostGIS.
Ceci a pour finalité d'ajouter les éléments dans le schéma de base qui est vide par défaut :

Comme présenté sur l'image, l'ajout de l’extension « postgis », dans les extensions d'une nouvelle base de données (ici, exemple_postgis), a ajouté les éléments suivants dans mon schéma par défaut public :
683 fonctions : fonctions d'analyse spatiale vectorielle (les outils rasters ont été séparés dans une autre sous-extension lors du passage à PostGIS 3.0),
1 table : spatial_ref_sys, : toutes les références des systèmes de coordonnées, sur lesquelles PostgreSQL se basera pour connaître la projection d'une table,
2 fonctions trigger (vérification d'autorisations et cache bbox pour PostGIS),
2 vues de gestion des tables vectorielles (géométries et géographies),
9 types de données spécifiques à PostGIS tels que la géométrie (geometry).
Les requêtes SQL et la création d'objets
Bien que l'on puisse créer la plupart des objets à partir d'un clic-droit sur le niveau à créer ou le niveau supérieur (par exemple, un clic-droit, sur le niveau Schémas, ou sur le nom de la base de données dans l'arborescence, puis Ajouter un objet, permet d'ajouter un schéma), la plupart des actions se réalisent à partir de l'éditeur SQL.
On conservera le clic-droit pour la création de bases de données sur le modèle de postgres, et pour les schémas sur le modèle de public.
Pour lancer une requête SQL, on se place à l'endroit où l'on désire créer un objet dans l'arborescence, et on clique sur le bouton du requêteur :


Attention :
Attention à l'endroit surligné (donc sélectionné) dans l'arborescence de gauche lors du lancement du requêteur ! Il conditionne la base de données sur laquelle la requête va avoir un impact.
Il serait fâcheux d'altérer des bases de données en production !
Veiller à toujours regarder l'entête du requêteur pour vérifier sur quelle base de données vous travaillez :

La création d'une table “nous” (2 colonnes : id, nom) se réalise par clic-droit sur tables et par paramétrages manuels OU par saisie de la phrase ci-dessous dans le requêteur SQL :
CREATE TABLE nous (id serial PRIMARY KEY, nom text);