Sauvegarde logique (dump)
Sauvegarder (pg_dump) avec PgAdmin
Le principe est de produire un fichier texte de commandes SQL (appelé « fichier dump »), qui, si on le renvoie au serveur, recrée une base de données identique à celle sauvegardée. PostgreSQL propose pour cela le programme utilitaire pg_dump. L'usage basique en ligne de commande est :
pg_dump base_de_donnees > fichier_de_sortie
la sauvegarde peut être effectuée depuis n'importe quel ordinateur ayant accès à la base. Pg_dump doit avoir un accès en lecture à toutes les tables que vous voulez sauvegarder, donc pour sauvegarder une base complète, vous devez pratiquement toujours utiliser un superutilisateur.
Un des gros avantages de pg_dump sur les autres méthodes de sauvegarde est que la sortie de pg_dump peut être généralement re-chargée dans des versions plus récentes de PostgreSQL, alors que les sauvegardes au niveau fichier et l'archivage continu sont tous les deux très spécifiques à la version du serveur. Pg_dump est aussi la seule méthode qui fonctionnera lors du transfert d'une base de données vers une machine d'une architecture différente (par exemple d'un serveur 32 bits à un serveur 64 bits).
Les options de la Pg_dump en ligne de commande sont décrites ici
Nous allons les examiner au travers de l'interface de pgadmin :
Méthode :
Sous pgadmin Clic droit sur une base → sauvegarder (ou menu Outils → sauvegarder).
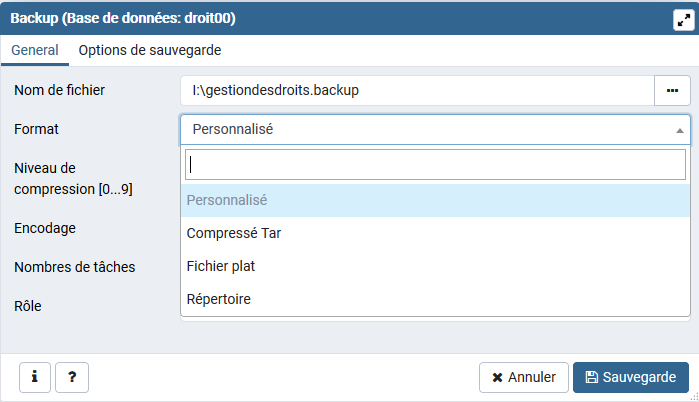
Les différents formats sont proposés :
Personnalisé : archive personnalisée utilisable par pg_restore. Avec le format de sortie répertoire, c'est le format le plus souple, car il permet la sélection manuelle et le réordonnancement des objets archivés au moment de la restauration. Ce format est aussi compressé par défaut.
Tar : archive tar utilisable par pg_restore. Le format tar est compatible avec le format répertoire; l'extraction d'une archive au format tar produit une archive au format répertoire valide. Toutefois, le format tar ne supporte pas la compression et a une limite de 8Go sur la taille des tables individuelles. Par ailleurs, l'ordre de restauration des données des tables ne peut pas être changé au moment de la restauration.
Fichier plat : fichier de scripts SQL en texte simple. Ce format offre une grande souplesse à la restauration des données, lors d'un changement de version de PostgreSQL ou pour utiliser les données dans d'autres SGBD.
Répertoire : Produire une archive au format répertoire utilisable en entrée de pg_restore. Cela créera un répertoire avec un fichier pour chaque table et blob exporté, ainsi qu'un fichier appelé Table of Contents (Table des matières) décrivant les objets exportés dans un format machine que pg_restore peut lire. Une archive au format répertoire peut être manipulée avec des outils Unix standard; par exemple, les fichiers d'une archive non-compressée peuvent être compressés avec l'outil gzip. Ce format est compressé par défaut et supporte les sauvegardes parallélisées.
Les autres options sont :
Encodage : Par défaut, la sauvegarde utilise celui de la base de données
Nombre de tâches : Exécute une sauvegarde parallélisée. Cette option réduit la durée de la sauvegarde mais, elle augmente aussi la charge sur le serveur de base de données. Vous ne pouvez utiliser cette option qu'avec le format de sortie répertoire car c'est le seul format où plusieurs processus peuvent écrire leurs données en même temps.
Rôle : Spécifie un rôle à utiliser pour créer la sauvegarde. Avec cette option, pg_dump utilise une commande SET ROLE nomrole après s'être connecté à la base. C'est utile quand l'utilisateur authentifié n'a pas les droits dont pg_dump a besoin, mais peut basculer vers un rôle qui les a. Certaines installations ont une politique qui est contre se connecter directement en tant que superutilisateur, et l'utilisation de cette option permet que les extractions soient faites sans violer cette politique.
Méthode : Onglet "Options de sauvegarde"
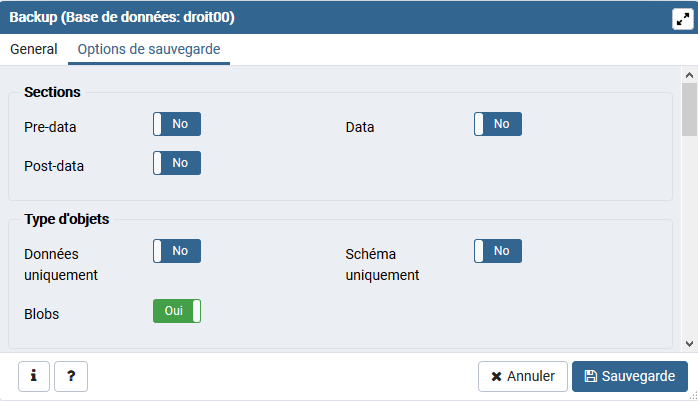
Sections : Sauvegarde seulement les sections indiquées (pre-données, données ou post-données). (Par défaut toutes les sections).
La section ‘données' contient toutes les données des tables ainsi que la définition des Large Objects et les valeurs des séquences.
Exemple en SQL : COPY commune (id, geom, ...)
Les éléments ‘post-données' incluent la définition des index, triggers, règles et contraintes (autres que les contraintes de vérification).
Exemple en SQL :
ALTER TABLE ONLY "TRONCON_ROUTE"
ADD CONSTRAINT "TRONCON_ROUTE_pkey" PRIMARY KEY (id);
Les éléments ‘pré-données' incluent tous les autres éléments de définition.
Exemple en SQL : CREATE TABLE commune (id integer NOT NULL,...)
Type des objets :
Données uniquement : (--data-only). Seules les données sont sauvegardées, pas le schéma (définition des données). Les données des tables, les Large Objects, et les valeurs des séquences sont sauvegardées. Cette option est similaire à cocher ‘données' dans ‘sections' mais, pour des raisons historiques, elle n'est pas identique.
Schéma uniquement : Seule la définition des objets (le schéma) est sauvegardée, pas les données. Cette option est l'inverse de ‘données uniquement'. Elle est similaire, mais pas identique (pour des raisons historiques), à cocher Pré-données et post-données dans ‘sections'.
Blobs : Inclut les objets larges (blob) dans la sauvegarde. C'est le comportement par défaut, sauf si une des options suivantes est ajoutée : --schema, --table ou --schema-only. L'option -b n'est utile que pour ajouter les objets larges aux sauvegardes sélectives.
Ne pas sauvegarder :
propriétaire (--no-owner) : Les commandes d'initialisation des possessions des objets au regard de la base de données originale ne sont pas produites. L'option -O est utilisée pour créer un script qui puisse être restauré par n'importe quel utilisateur. En revanche, c'est cet utilisateur qui devient propriétaire de tous les objets à la restauration.
Droits (--no-privileges ) : Les droits d'accès (commandes grant/revoke) ne sont pas sauvegardés.
Tablespace (--no-tablespaces ) : Ne pas générer de commandes pour créer des tablespace, ni sélectionner de tablespace pour les objets. Avec cette option, tous les objets seront créés dans le tablespace par défaut durant la restauration.
Données de la table non enregistrées dans les journaux (--no-unlogged-table-data ) : Ne pas exporter le contenu des tables non journalisées (unlogged)
Méthode : Options de sauvegarde (suite)
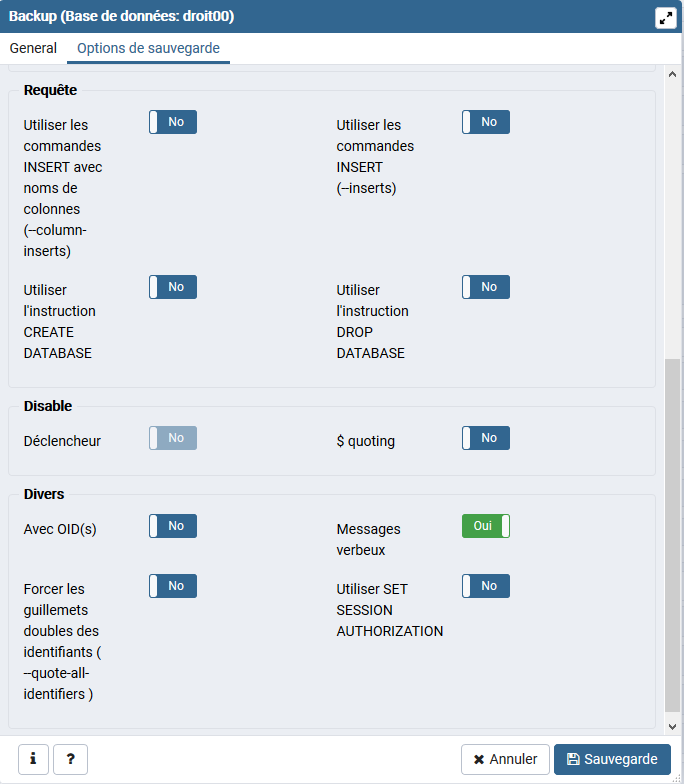
Requêtes :
Utiliser les INSERT avec noms de colonnes (--column-inserts ) : Extraire les données en tant que commandes INSERT avec des noms de colonnes explicites (INSERT INTO table (colonne, ...) VALUES ...). Ceci rendra la restauration très lente ; c'est surtout utile pour créer des extractions qui puissent être chargées dans des bases de données autres que PostgreSQL.
Utiliser des commandes INSERT (--inserts ) : Extraire les données en tant que commandes INSERT (plutôt que COPY). Ceci rendra la restauration très lente ; c'est surtout utile pour créer des extractions qui puissent être chargées dans des bases de données autres que PostgreSQL, Notez que la restauration peut échouer complètement si vous avez changé l'ordre des colonnes. L'option --column-inserts est plus sûre, mais encore plus lente.
Utiliser l'instruction CREATE DATABASE (--create ) : La sortie de sauvegarde débute par une commande de création de la base de données et de connexion à cette base. Peu importe, dans ce cas, la base de données de connexion à la restauration. De plus, si --clean est aussi spécifié (DROP DATABASE), le script supprime puis crée de nouveau la base de données cible avant de s'y connecter
Utiliser l'instruction DROP DATABASE (--clean): Les commandes de nettoyage (suppression) des objets de la base sont écrites avant les commandes de création.
Désactiver :
trigger (déclencheurs) (--disable-triggers ) : Cette option ne s'applique que dans le cas d'une extraction de données seules. Ceci demande à pg_dump d'inclure des commandes pour désactiver temporairement les triggers sur les tables cibles pendant que les données sont rechargées. Utilisez ceci si, sur les tables, vous avez des contraintes d'intégrité ou des triggers que vous ne voulez pas invoquer pendant le rechargement. Cette option n'a de sens que pour le format texte simple (SQL). Pour les formats d'archive, vous pouvez spécifier cette option quand vous appelez pg_restore. À l'heure actuelle, les commandes émises pour --disable-triggers doivent être exécutées en tant que superutilisateur.
Guillemet dollar (--disable-dollar-quoting ) : Cette option désactive l'utilisation du caractère dollar comme délimiteur de corps de fonctions, et force leur délimitation en tant que chaîne SQL standard.
Divers :
Avec OID (--oids ) : Les identifiants d'objets (OID) sont sauvegardés comme données des tables. Cette option est utilisée dans le cas d'applications utilisant des références aux colonnes OID (dans une contrainte de clé étrangère, par exemple). Elle ne devrait pas être utilisée dans les autres cas.
Message en verbeux (--verbose ) : Mode verbeux. pg_dump affiche des commentaires détaillés sur les objets et les heures de début et de fin dans le fichier de sauvegarde. Des messages de progression sont également affichés sur la sortie d'erreur standard.
Forcer les guillemets doubles des identifiants (--quote-all-identifiers ) : Force la mise entre guillemets de tous les identifiants. Ceci peut être utile si vous exportez votre base en vue d'une migration dans une nouvelle version qui aurait introduit de nouveaux mots clés.
Utilisez SET SESSION AUTHORIZATION (--use-set-session-authorization): Émettre des commandes SQL standard SET SESSION AUTHORIZATION à la place de commandes ALTER OWNER pour déterminer l'appartenance d'objet. Ceci rend l'extraction davantage compatible avec les standards, mais, suivant l'historique des objets de l'extraction, peut ne pas se restaurer correctement. Par ailleurs, une extraction utilisant SET SESSION AUTHORIZATION nécessitera certainement des droits superutilisateur pour se restaurer correctement, alors que ALTER OWNER nécessite des droits moins élevés
Méthode : rapport de sauvegarde
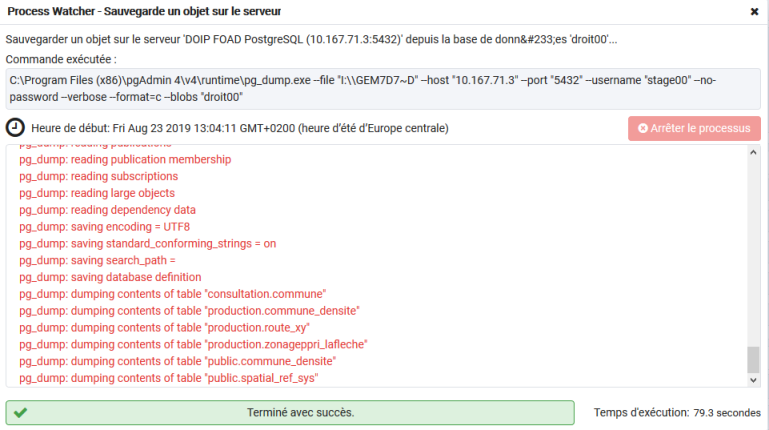
Pendant la sauvegarde un message apparaît :
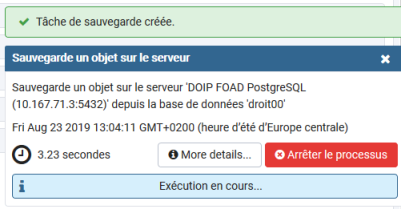
Il est possible de demander plus de détails sur la sauvegarde avec le bouton 'More détails...'
Complément :
En ligne de commande, il est possible de ‘dumper' une base directement dans une autre sans passer par un fichier intermédiaire.
La commande sera du type :
pg_dump -h serveur1 base_de_donnees | psql -h serveur2 base_de_donnees
Conseil :
Après la restauration d'une sauvegarde, il est conseillé d'exécuter ANALYZE sur chaque base de données pour que l'optimiseur de requêtes dispose de statistiques utiles.
On utilise pour cela le menu Outils-> maintenance puis ANALYZE.