Bases et schémas
L'organisation générale d'un serveur PostgreSQL est la suivante.
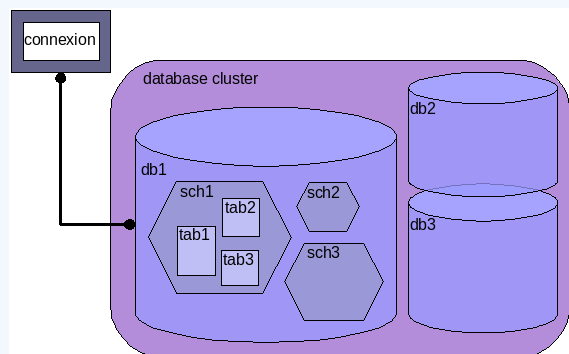
A l'installation du serveur un emplacement de stockage pour les bases de données a été initialisé. Ceci est appelé ‘groupe de bases de données' ou encore ‘grappe de base de données' (database cluster en anglais). Un groupe de bases de données est une collection de bases données et est géré par une seule instance d'un serveur de bases de données en cours d'exécution. Plusieurs groupes de bases de données peuvent fonctionner en même temps sur le même serveur.
Une instance correspond à une exécution du serveur PostgreSQL. Un groupe de base de données correspond à un conteneur de bases de données sous la forme de répertoires et de fichiers. Chaque instance dispose de ses structures mémoires, ses processus, son arborescence de fichiers, ses fichiers de configuration, son port d'écoute,...(pour l'administrateur système voir la commande INITBD)
Un ‘cluster' de bases de données contient une ou plusieurs base(s) nommée(s).
Conseil : Organisation en bases et schémas
Toute connexion cliente au serveur ne peut accéder qu'aux données d'une seule base, celle indiquée dans la requête de connexion. Il est donc important de bien organiser ses bases et de privilégier l'utilisation des schémas (voir ci-dessous) dans une même base de données pour les tables que l'on souhaite inter-opérer. Le ‘cross-database' reste toutefois possible (avec Dblink ou Foreign data wrapper). Nous en verrons un exemple dans ce cours.
Une base de données contient un ou plusieurs schéma(s) nommé(s) qui, eux, contiennent des tables. Les schémas contiennent aussi d'autres types d'objets nommés (types de données, fonctions et opérateurs, par exemple). Le même nom d'objet peut être utilisé dans différents schémas sans conflit ; par exemple, schema1 et mon_schema peuvent tous les deux contenir une table nommée ma_table.
À la différence des bases de données, les schémas ne sont pas séparés de manière rigide : un utilisateur peut accéder aux objets de n'importe quel schéma de la base de données à laquelle il est connecté, sous réserve qu'il en ait le droit.
Il existe plusieurs raisons d'utiliser les schémas :
autoriser de nombreux utilisateurs à utiliser une base de données sans interférer avec les autres ;
organiser les objets de la base de données en groupes logiques afin de faciliter leur gestion ;
les applications tiers peuvent être placées dans des schémas séparés pour éviter les collisions avec les noms d'autres objets.
Pour créer les objets d'un schéma ou y accéder, on écrit un nom qualifié constitué du nom du schéma et du nom de la table séparés par un point ; schema.table
exemple :
CREATE TABLE mon_schema.ma_table (...
Par défaut (si le nom du schéma n'est pas spécifié) les données sont créées dans le schéma public, mais il est de bonne pratique de mettre les données dans d'autres schémas car cela permet de séparer le cœur de PostGIS (tables systèmes, fonctions,...) des données elles-mêmes et facilite par exemple les sauvegardes / restaurations ainsi que la gestion des droits.
Complément : Chemin de parcours des schémas
L'écriture des noms qualifiés (MonSchema.MaTable) peut être contraignante dans les requêtes SQL. De ce fait, les tables sont souvent appelées par des noms non-qualifiés, soit le seul nom de la table. Le système détermine la table appelée en suivant un chemin de recherche, liste de schémas dans lesquels chercher. La première table correspondante est considérée comme la table voulue. S'il n'y a pas de correspondance, une erreur est remontée, quand bien même il existerait des tables dont le nom correspond dans d'autres schémas de la base
Le premier schéma du chemin de recherche est appelé schéma courant. En plus d'être le premier schéma parcouru, il est aussi le schéma dans lequel les nouvelles tables sont créées si la commande CREATE TABLE ne précise pas de nom de schéma.
Le chemin de recherche courant est affiché à l'aide de la commande :
SHOW search_path;
Dans la configuration par défaut, ceci renvoie :
search_path
--------------
"$user",public
Le premier élément précise qu'un schéma de même nom que l'utilisateur courant est recherché. En l'absence d'un tel schéma, l'entrée est ignorée. Le deuxième élément renvoie au schéma public précédemment évoqué.
Par défaut, les utilisateurs ne peuvent pas accéder aux objets présents dans les schémas qui ne leur appartiennent pas. Pour le permettre, le propriétaire du schéma doit donner le droit USAGE sur le schéma
Par défaut, tout le monde bénéficie des droits CREATE et USAGE sur le schéma public. Ce privilège peut être révoqué :
REVOKE CREATE ON SCHEMA public FROM PUBLIC;
Le premier « public » est le schéma, le second «PUBLIC» signifie « tout utilisateur ». Dans le premier cas, c'est un identifiant, dans le second, un mot clé, d'où la casse différente.
Rappel : Convention de nommage
Une convention couramment utilisée revient à écrire les mots clés en majuscule et les noms en minuscule, exemple :
UPDATE ma_table SET a = 5;
Pour ajouter un schéma au chemin de recherche on écrit :
SET search_path TO mon_schema,public;
Si on omet public, le schéma public n'est plus accessible sans qualification explicite.
La modification des chemin de recherche par SET search_path n'est valide que pendant la session et sera perdue à la prochaine connexion.
Il est possible de modifier de façon permanente le chemin de recherche pour un utilisateur avec ALTER USER, Exemple :
ALTER USER alain SET search_path TO monschema, public ;
Conseil : Utilisation des schémas
Les schémas peuvent être utilisés avec différentes stratégies pour organiser les données
si aucun schéma n'est créé, alors tous les utilisateurs ont implicitement accès au schéma public. Cette situation n'est recommandée que pour un usage de PostgreSQL avec un utilisateur unique (usage bureautique).
pour chaque utilisateur, un schéma, de nom identique à celui de l'utilisateur, peut être créé. Le chemin de recherche par défaut commence par $user, soit le nom de l'utilisateur. Si tous les utilisateurs disposent d'un schéma distinct, ils accèdent, par défaut, à leur propre schéma (et n'ont pas à utiliser les noms qualifiés). Dans cette configuration, il est possible de révoquer l'accès au schéma public (voire de supprimer ce schéma) pour confiner les utilisateurs dans leur propre schéma ;
l'installation d'applications partagées (tables utilisables par tout le monde, fonctionnalités supplémentaires fournies par des applications tiers, etc) peut se faire dans des schémas distincts. Il faut alors accorder des privilèges appropriés pour permettre aux autres utilisateurs d'y accéder (nous y reviendrons). Les utilisateurs peuvent alors se référer à ces objets additionnels en qualifiant leur nom du nom de schéma ou ajouter les schémas supplémentaires dans leur chemin de recherche.