Créer des requêtes spatiales complexes
Réaliser des requêtes SQL
Objectif : créer une vue pour chaque question et réaliser des requêtes SQL
Question
Question 1 :
Charger les couches suivantes dans PostGIS comme vu précédemment :
/BD_TOPO/I_ZONE_ACTIVITE/PAI_SANTE.SHP
/BD_TOPO/H_ADMINISTRATIF/COMMUNE.SHP *
/BD_TOPO/E_BATI/BATI_INDUSTRIEL.SHP
/BD_TOPO/F_VEGETATION/ZONE_VEGETATION.SHP
* Attention, vous disposez déjà d'une couche "commune" dans le schéma, nommez-la donc "commune_topo" lors de l'import pour la différencier.
De plus, si vous ouvrez cette couche COMMUNE.SHP dans QGIS, vous remarquez que la colonne ID contient 2 fois la valeur SURFCOMM0000000112528241. Cette colonne, ne pourra donc pas servir de clé primaire lors de l'import : il faut donc cocher "clé primaire" et mettre "fid" par exemple (sans les guillemets) dans la fenêtre d'import.
Créer une nouvelle vue bati_industriel10 et la charger dans QGIS en sélectionnant dans la table bati_industriel les 'Bâtiment industriels' (attention à la majuscule!) dont la hauteur est d'au moins 10 m.
Indice
La vue résultat doit contenir 8 enregistrements.
QGIS n'aime pas les id en texte , il peut refuser d'ajouter la vue.
Vous pouvez l'observer depuis le menu Couche > Ajouter une couche > Ajouter une couche PostGIS :
Si vous vous connectez à votre BDD et schéma public : vous voyez que cette couche a un warning (triangle jaune), en vous positionnant dessus, il vous demande un id de l'entité pourtant id est bien coché : décochez-le et recochez-le, vous pouvez ensuite ajouter la couche.
Solution idéale : lorsque l'id est en texte (ce qui arrive souvent), doublez toujours l'id en ajoutant row_number() over() AS gid au début du SELECT comme expliqué dans le cours pour éviter les surprises des logiciels tiers (valables aussi pour les serveurs géographiques si vous en utilisez).
Question
Question 2 :
Créer la vue conifere les 'Forêt fermée de conifères' de la commune de La Flèche. Ne pas oubliez de mettre une condition de jointure entre les deux couches... qui devra être ici spatiale.
Indice
La vue résultat doit contenir 55 enregistrements.
Question
Question 3 (plus difficile...) :
Calculer la somme des surfaces des 'Forêt fermée de feuillus' de la commune de la Flèche en ha (1ha = 10 000 m2), en faisant attention à ne prendre en compte que les parties de surfaces des polygones réellement situées à l'intérieur de la commune.
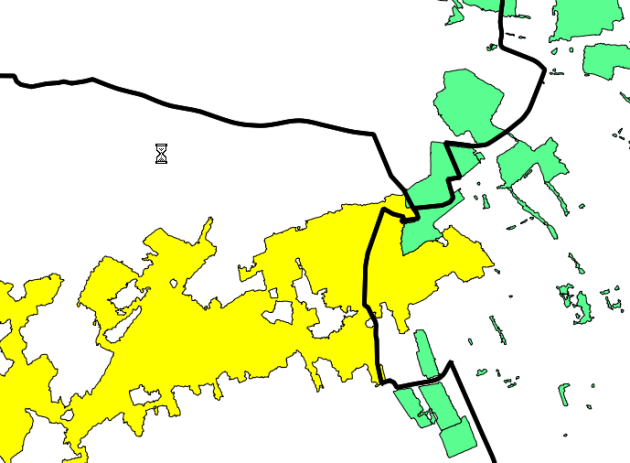
Ainsi dans l'exemple ci-dessus il ne faut prendre en compte que la partie du polygone jaune qui est à l'intérieur de la commune de la Flèche... on pourra penser à la fonction ST_Intersection() qui retourne un objet géométrique intersection de deux objets...le résultat est 565 ha
Question
Question 4 :
Construire une nouvelle vue (non graphique) de nom etablis_plus_proche qui pour chaque établissement hospitalier de la couche pai_sante donne l'identifiant (ID) de l'établissement industriel de la couche bati_industriel le plus proche, ainsi que la distance
ATTENTION :
Cet exercice fait appel pour sa solution à l'utilisation d'une sous-requête, il peut être jugé complexe, dans ce cas essayez de comprendre la solution. Son objectif est de montrer la puissance du SQL pour la résolution de problèmes parfois complexes...
Le résultat est :

Indice
Il est conseillé de décomposer un problème complexe en problèmes plus simples pour arriver à la solution...
On pourra dans un premier temps construire une table qui donne les distances de tous les établissements industriels de la couche bati_industriel pour chaque établissement hospitalier. Il faut pour cela utiliser les deux tables pai_sante et bati_industriel. On notera qu'on ne peut donner une condition de jointure, ni attributaire (pas de champ commun), ni géographique (les objets ne se superposent pas). Dans ce cas on peut construire le produit des deux tables (produit cartésien) sans condition (ce que n'autorise pas MapInfo).
SELECT * FROM pai_sante, bati_industriel
Il reste à ajouter la colonne donnant les distances.
ATTENTION : Faire un produit cartésien sur deux tables sans condition de jointure doit être réservé à des tables de petite dimension.
Note : Pour éviter de faire le produit cartésien complet, on pourrait penser à utiliser sous PostGIS la fonction ST_Dwithin() avec un rayon de recherche maximum.
La table précédente peut nous donner accès pour chaque pai_sante à la distance minimum de l'établissement le plus proche avec un GROUP BY
SELECT pai_sante.id, MIN(ST_Distance(pai_sante.Geom, bati_industriel.Geom)) AS distance_min
FROM pai_sante,bati_industriel
GROUP BY pai_sante.id
On pourrait penser à demander dans le tableau bati_industriel.id... mais le résultat serait faux, car il ne faut pas oublier lorsqu'on utilise un GROUP BY que chaque colonne en sortie (dans la clause SELECT) doit être, soit le critère de rupture (celui du GROUP BY), soit être le résultat d'une fonction d'agrégation...(sous PostGIS vous aurez d'ailleurs un message du type
ERREUR : la colonne "bati_industriel.id" doit apparaître dans la clause GROUP BY ou être utilisée dans une fonction d'agrégation
Nous voila donc avec le tableau suivant :
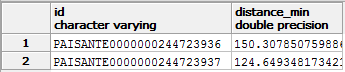
Il faut maintenant trouver les couples (pai_sante.id bati_industriel.id) pour lesquels la distance est l'une ou l'autre des distances de la table précédente... autrement dit exécuter une requête du type :
SELECT... ST_Distance(...) as distance FROM pai_sante, bati_industriel WHERE ST_Distance(...) IN (... résultat de la requête donnant les deux distances minimum)